Organization and reference group structure
DeiC coordinates the national digital research infrastructure as a collaboration with and between the Danish universities.
DeiC's legal basis is described in Executive Order BEK 615 of 26/05/2023.
DTU is the host university for DeiC, and the employees are employed at DTU.
DeiC is managed by a board, which on behalf of the universities is responsible for the overall and strategic management and operation of the collaboration.
The board appoints a director for DeiC, who handles the daily management. The director is employed at the host university.
The day-to-day management is responsible for DeiC's operational activities, development activities, collaboration projects and other initiatives decided by the board.
DeiC's board
The board is appointed by the Danish Agency for Higher Education and Science on the recommendation of Universities Denmark and consists of one person from the management level at each university.
Organization chart
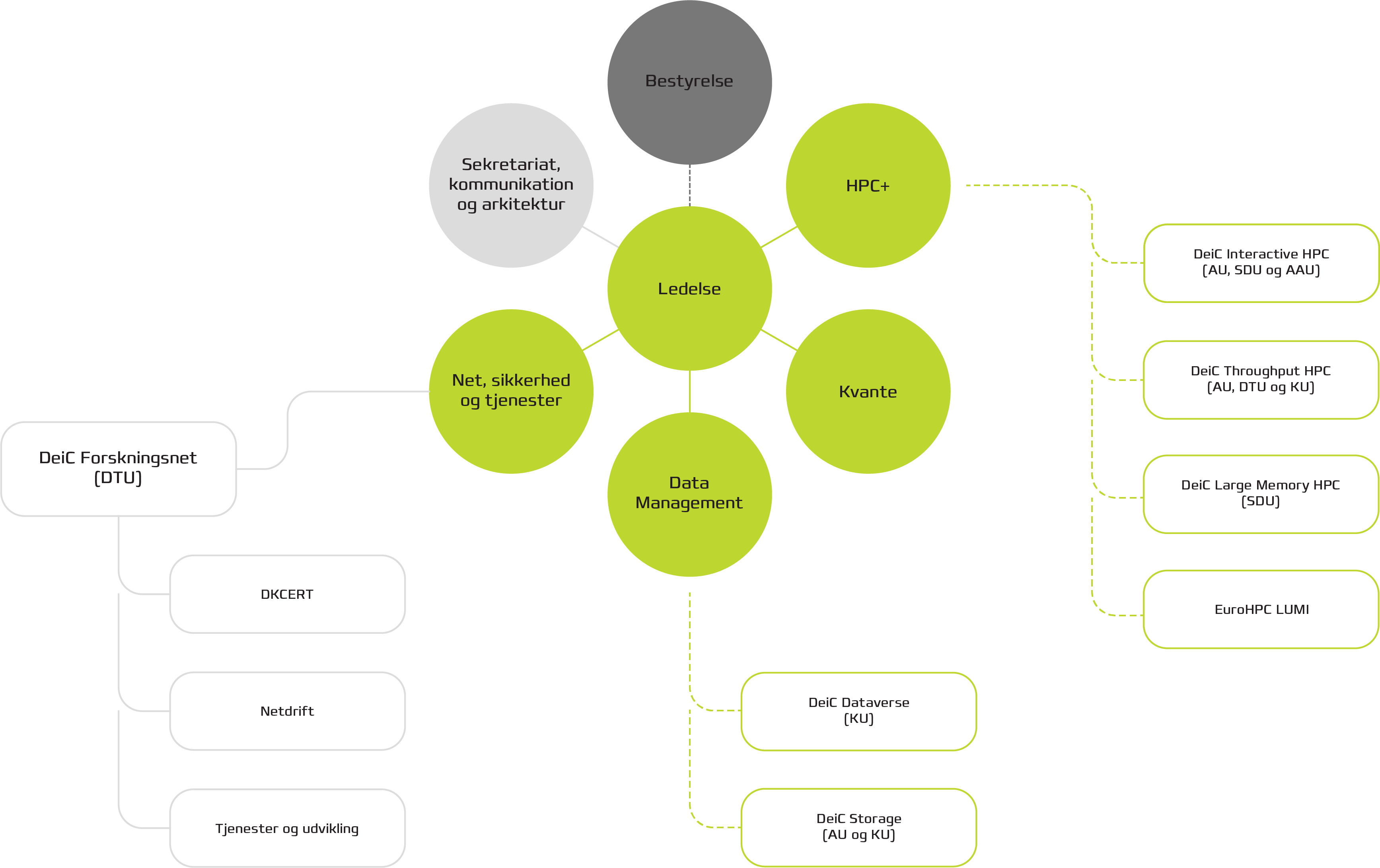
Management structure
The day-to-day manager of DeiC and responsible to the Board of Directors is Acting Director Martin Bech. In addition to the Director, the management team consists of Head of HPC+ Rune Gamborg Ørum, Head of Data Management Anne Sofie Fink Kjeldgaard and Head of Quantum Henrik Navntoft Sønderskov.
DeiC coordinates the delivery of the digital research infrastructure provided by the universities.
DeiC Forskningsnettet is operated by DTU. DeiC Forskningsnettet is considered a "subsidiary" of DeiC, and DeiC's Board of Directors is responsible for finances and service portfolio. Head of Forskningsnettet Martin Bech reports to DeiC's director for the activities covered.
The delivery of the other infrastructure services from the universities is regulated through agreements.
Reference groups
To ensure a good dialogue with the universities and involve the users of the digital research infrastructure in the national development, DeiC's board has established a number of reference groups. The members of the reference groups are nominated by their universities and represent the university in the reference group. The exception to this is the members of the Science Forum, who are nominated in their personal capacity.
The reference groups are divided according to the time frame of their activities.
Operation
The operation of the DeiC Research Network and its services is handled by the Head of the Research Network with reference to DeiC's director.
The operation of the other infrastructure is handled by universities that have bid for the task. The daily operation will be coordinated across the so-called "Back Office" units, consisting of the operations managers from the universities and the head of HPC+ and Data Management at DeiC.
The head of DeiC chairs the relevant back office collaboration.
In addition to the Back Office units, a distribution committee (e-resource committee) has been established to receive and process applications for access to the national resources in the HPC and data management area.
The Coordinating Body for Register Research (KOR) is an advisory body under DeiC with reference to the DeiC Board. KOR aims to stimulate and strengthen Danish register research and contribute to creating greater coherence and coordination of Danish and internationally related research activities concerning registers and databases.
1-3 year aim
The purpose of the reference groups for the 1-3 year aim is to follow the activities nationally and internationally in DeiC's main areas (HPC, data management and research networks and services) and advise the board on services, activities and initiatives in the area.
Net Forum aims to advise on developments in research networks, functional security and services. The group consists of infrastructure managers from the universities. The current members of the group are appointed for the period July 1, 2021 - June 30, 2023.
The purpose of the HPC Forum is to advise DeiC's Board of Directors on the development of the national HPC infrastructure, participation in international collaborations and projects and other initiatives to promote HPC use in Denmark. The current members of the group are appointed for the period January 1, 2023 - December 31, 2025.
DM Advisory Forum aims to advise DeiC's Board of Directors on the development of the national data management infrastructure, participation in international collaborations and projects and other initiatives to promote the area. The current members of the group are appointed for the period January 1, 2023 - December 31, 2025.
Vision
The purpose of the Science Forum is to ensure a development of the infrastructure that meets future needs. The members of the group are researchers who use the infrastructure and are at the forefront of its use.
Communities
The purpose of communities is to provide a space for sharing experiences across universities in a specific area in a more informal structure.
HPC TekRef (technical reference group for HPC) is a forum for sharing experiences between the local and national HPC centers. Members are typically system administrators. The chairman of the group is elected by the participants.
Net TekRef (Network Technical Reference Group) is a forum for the exchange of experience between the network and service operation units at universities and research network operations and services. Members are typically network administrators from the universities. The chairman of the group is elected by the participants.