The Danish GO FAIR office is part of GO FAIR international. The office's aim is to implement FAIR data management principles in Denmark to improve the findability, accessibility, interoperability and reuse of digital research assets. It is in line with the national strategy for FAIR Data Management.
The GO FAIR implementation is about FAIRification initiatives in practice by research groups, communities and through GO FAIR Implementation Networks (IN's) assisted by the GO FAIR International Support and Coordination Office (ISCO).
The purpose of the Danish GO FAIR office is to facilitate the opportunity for Danish universities to support research groups in their FAIRification initiatives. To achieve this, we at DeiC use a further developed version of GO FAIR's FAIRification process. You can find it below. This process described on this page gives you more options and tools to obtain FAIR data.
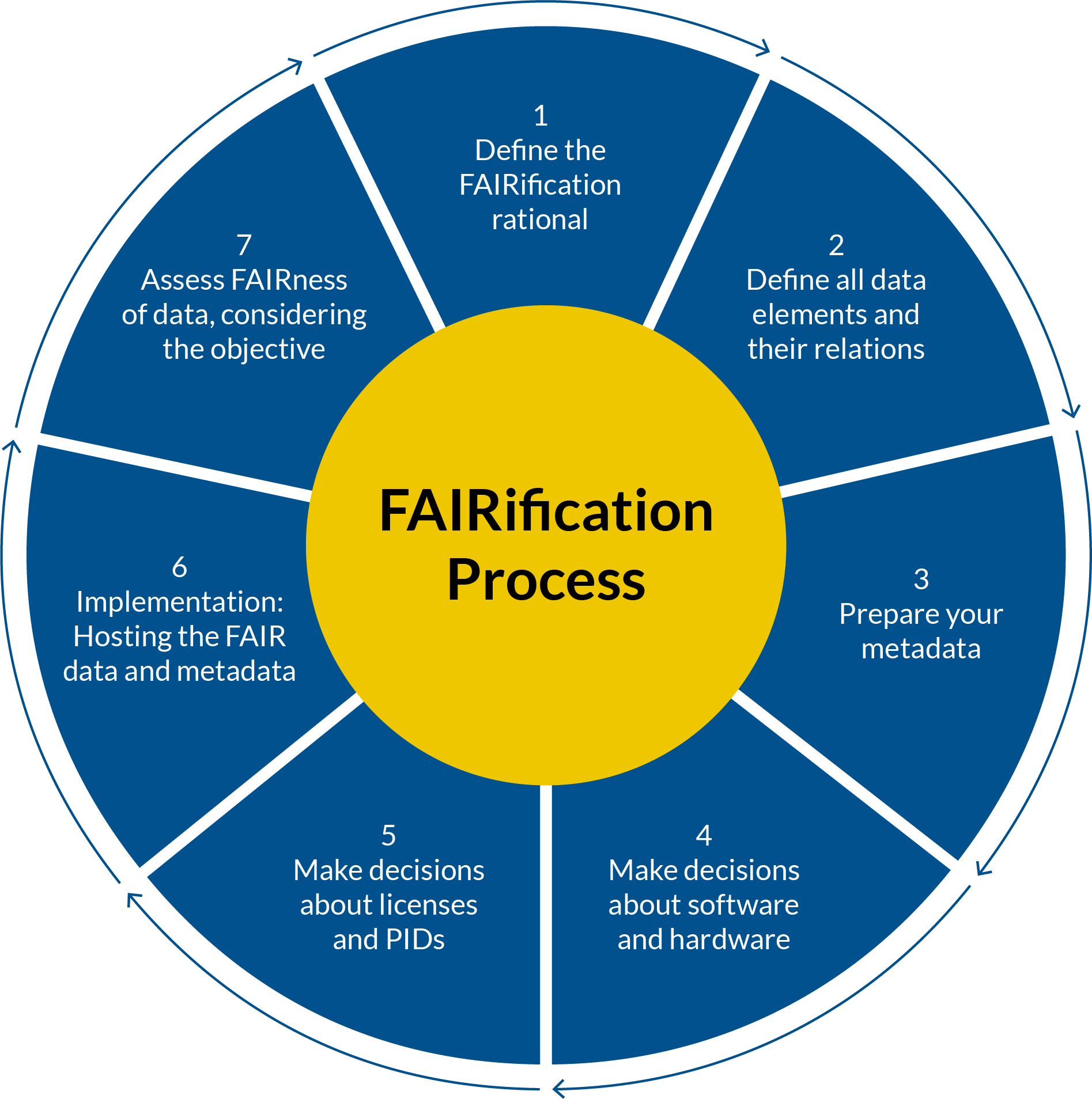
1. Define the FAIRification rational for your data
- Clarify why FAIRification and/or open access to your research data must be pursued e.g. data that need to be referenced by an research publication.
- Assess FAIRness of data to decide which metrics need improvement. Not all metrics have to be perfectly fulfilled; different research areas/groups might have different requirements and needs.
- Choose datasets for FAIRification. Prioritise newly produced data and data with potential for reuse over already existing data.
- Define who should have access to your data (domain-specific vs. broader audience).
As a starting point it can help to use a FAIR data assessment tool (e.g. F-UJI or FAIR evaluator) to get an overview over the FAIR condition of your data. Don't get discouraged if your data don't score a 100%. The goal of making your data FAIR is not necessarily to get a perfect score in a FAIR assessment tool. These tools can be very useful conversation starters and can help you think about what properties of your data or metadata can be adjusted in order to be more FAIR.
2. Define all data elements and their relations

- Analyse the content of the data in terms of structure and concepts represented.
- Check, if there is an already existing vocabulary or ontology from your research domain available e.g. BioPortal.
- If necessary, add elements to an existing vocabulary to fit your needs or build a new vocabulary.
3. Prepare your metadata
- Use an existing metadata template such as a generic metadata templates structured in the DCAT organisation (requires CEDAR login) or, if not available, create one preferably in agreement with your research domain.
- Use the chosen vocabulary to describe the meaning of data elements and relations – accurately, unambiguously, preferably in a machine-actionable way to support interoperability.
- Decide on licensing (who can access the data and how can it be used) e.g. a Creative Commons license.
- Link metadata to datasets for instance in a database.
Extensive and machine readable metadata is a very important cornerstone in order to make your data FAIR. A Metadata for Machines (M4M) workshop (M4M by GO FAIR foundation and M4M by DeiC) can help in making your metadata as FAIR as possible. During an M4M workshop you are creating a machine actionable ontology for your domain specific metadata, using relatively simple tools like GoogleSheets and GitHub. To increase convergence, check if other research groups from your community have already created an ontology you can re-use or build upon. It is little helpful to create a new ontology for every small research area/group.
4. Make decisions about software and hardware to support FAIRification

- Decide which database or data repository your data and metadata should be stored in.
- Secure sustainable operations (service level agreements, costing etc.), preferably also after the original research grant runs out.
5. Make decisions about licenses and PIDs
- Decide under what license your data should be published, e.g. a Creative Commons license.
- Decide which Persistent IDentifier (PID) is the right one for your use case e.g. DOI.
A FAIR Implementation Profile (FIP) can help you make these decisions. Check if there are any requirements from your institution or the funder of your research project.
When you feel like you have a good overview of the technical aspects of data publishing, use the FIP-wizard to create your own FAIR implementation profile (FIP). Compare it with FIPs from other research area/groups in your community and possibly make adjustments in your choices to increase convergence and interoperability.
6. Implementation: Hosting your FAIR data and metadata

- Implement and test operational databases, including external access and queries.
- Or, export data to a repository that is well-suited for hosting FAIR data.
- If you decide upon a repository, look for a certified digital repository, for instance with the Core Trust Seal Certification.
A FAIR Data Point (FDP) can be a good choice for hosting your metadata. An FDP is a metadata repository based on the DCAT organisation. If you have some technical knowledge (or a Data Steward in your team) you can set up a FDP yourself. It enables you to have full control over your metadata, so you can make changes and updates, add your metadata, while having it published on the internet for everyone to find and re-use.
7. Assess FAIRness of data, considering the objectives for your FAIRification effort
- Re-assess FAIRness of your data.
- If there is still room for improvement, restart from the top.
Using a FAIR assessment tool can again help you with evaluating the FAIRness of your data. Remember, that the goal is not to score a 100%, but to help you think about which F-A-I-R elements are important to improve and which are not adding much benefit in your specific case.
If you are interested in knowing more, you are always welcome to contact Hannah.Mihai@deic.dk.




