Andreas Larsen Engholm and Jesper Strøm chuckle a bit when it's mentioned during the interview that, as students, they've already made a significant contribution to research. Nevertheless, it's true because the back-end tools these two young men have developed to train selected sleep scoring models on the LUMI supercomputer will be freely available on GitLab in a user-friendly form. These tools will make it easier for future researchers to load more sleep data. More data leads to better sleep scoring models and more accurate interpretations of sleep data because neural networks become increasingly skilled at automatically reading sleep stages correctly.
Machine Learning with Big Data in Sleep Scoring/Sleep Research
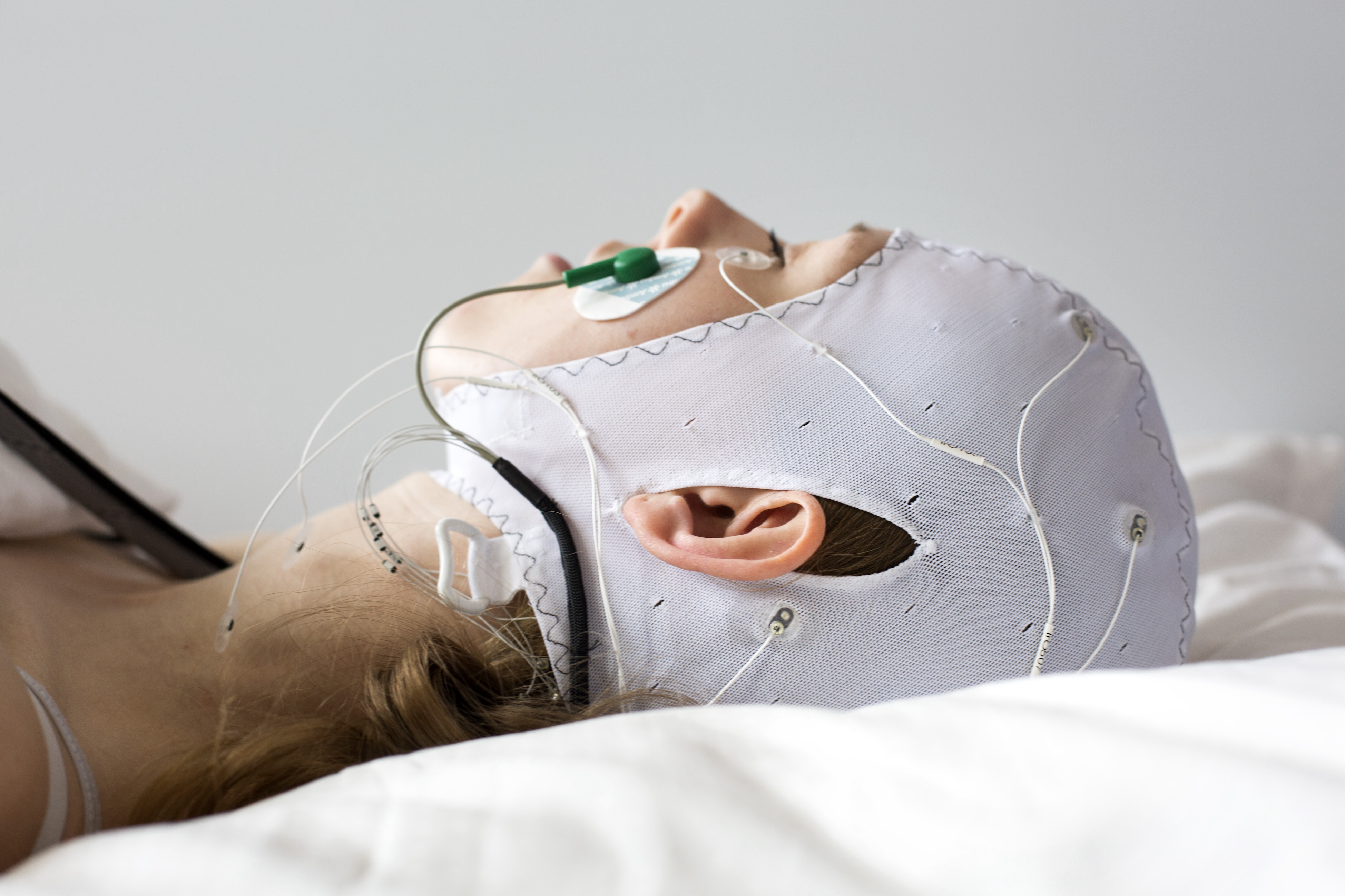
In fact, it was Jesper and Andreas' thesis advisor, Assistant Professor and sleep researcher Kaare Mikkelsen (Aarhus University, Denmark), who suggested that Jesper and Andreas delve into machine learning in sleep scoring using some favorite models to see how well it could perform with big data compared to trained sleep specialists - in other words, humans. In the field of sleep scoring, there exists a "gold standard," where a sleep expert, using a manual, determines the sleep stage of the individual sleeper every 30 seconds throughout a night’s recording. This is a task that calls for automation. Can we create an analysis model that replicates what a sleep expert would have answered? It's not a straightforward task because of differences in culture, measuring devices, etc. How can we still derive meaningful results, and when do we reach a point where our machine learning model becomes a better standard than humans who are observing? That was the starting point.
LUMI enters the Picture
1. When: April to June 2023
2. Allocation: 5000 Terabyte hours, 3500 GPU hours on LUMI via DeiC's "Sandbox"
3. Solution: Software designed to run on parallel GPU nodes and temporary storage of up to 50 TB of data
4. Student: Andreas Larsen Engholm, M.Sc. Computer Engineering, AU
5. Student: Jesper Strøm, M.Sc. Computer Engineering, AU
6. Advisor: Kaare Mikkelsen, Assistant Professor, Biomedical Technology, Department of Electrical and Computer Engineering, AU
Kaare Mikkelsen became aware of LUMI's computing power through his Associate Dean, Brian Vinther, AU, and with Jesper and Andreas' expertise in computer technology, it was clear that they could benefit greatly from working on LUMI for their project. Their task was to train neural networks to perform sleep scoring based on 20,000 PSG (Polysomnography) recordings to see the impact of working with such a large dataset. Could the models come close to the results of other research projects? It was all about how well they could train the neural networks.
The Work Begins: Normalizing 21 Datasets Takes Time
The project started on AU's own data infrastructure, which the two students were already familiar with. However, even in the preparation phase, when only 1/5 of the dataset was uploaded, they encountered an error message stating that the data took up too much space. This accelerated the process of getting started on LUMI. Andreas and Jesper received an introduction on how to use SLURM [LUMI uses the SLURM Workload Manager queuing system], and they had to build their container (a software tool for computations).
"We downloaded all the data directly from the internet to LUMI using scripts we developed ourselves. Then we had to start preprocessing, which involves processing the data so that all our 21 different datasets were in the format we wanted, which is the format the sleep scoring model was originally designed for. The 21 datasets came from various places around the world and were in different folder structures and file formats. Additionally, the two sleep scoring models we were comparing expected input in different formats," the two students explain.
A significant part of the work in this project involved programming the back end to being able to load 20,000 nights' worth of data (which was the sum of the 21 datasets) in a sensible way. Jesper and Andreas had to think through the systematics and approach to this. How do we do this in a way that is scientifically sound? It's important so that others can come in and see exactly how they did it, allowing for future expansion if other datasets emerge. The significant work done here can enable others to quickly get up to speed and do it in much less time than the 4 months it took Andreas and Jesper.
"The major work of normalizing all the data for our models was actually what took the longest time, and that preprocessing pipeline is now accessible to other researchers and students, making it much easier to load dataset number 22. We emphasized finding a sustainable, scalable solution that could be used by others in the future," Jesper Strøm says.

Significant Improvement in Sleep Score Models by Using a Lot of Data
Andreas and Jesper have demonstrated a significant improvement in sleep score models by using a large amount of data. They have come close to the results they were testing against but are still slightly off. They have also discovered that there is a difference between the two models despite using the same method. It actually appears that one model is slightly better than the other.
Without LUMI, it would not have been possible to train the models in the way they did. The alternative would have been to train on one of the large datasets, which might take up 500 GB (instead of multiple datasets). They would have figured out which model performs best on that specific dataset. This approach would not have allowed them to achieve the breadth and generalization they obtained. Using more datasets improves representativeness. They tried to compare the results of running on the full dataset versus running on 10% of the dataset, and there was a clear improvement when using a lot of data.
"If we didn't have LUMI, we probably would have had to work with just 10%, and our results wouldn't have been as good," Andreas Larsen Engholm explains.
Good LUMI Support and Significant Learning
The project received computing time in DeiC's "Sandbox” over a period of 4 months allocated for the thesis project.
"Throughout the project, we've had great support from DeiC, which had connections to LUMI. We were granted additional computing time in DeiC's ‘Sandbox’ multiple times because we kept realizing that we needed more. Much of our time was spent learning how to use LUMI, especially how not to write job scripts," Jesper Strøm laughs.
For future projects, the plan is to use a combination of the local machine at AU and LUMI.
"When we just need to check how the code should be designed, we will probably continue doing it locally and not use external resources. Now we've learned quite a bit, including the process, and our own system admin here at AU has also learned to support the setup," Andreas Larsen Engholm explains.
The plan is also to find an easier way to transfer data from AU to LUMI in future projects. There is a planned data infrastructure at AU, which will make working with data much easier. Data transfer has been the most cumbersome aspect of a data-heavy project.
"We've been more data-heavy than compute-heavy in this project," Andreas Larsen Engholm adds.
Without LUMI, we probably would have abandoned the project
The project utilized a total of 3500 GPU hours. If a single GPU had done the work, it would have taken 145 days, longer than the entire 4-month thesis period.
"In reality, we probably would have abandoned the project if we didn't have access to LUMI. We would have had to move data back and forth because there wasn't enough space, making it very inconvenient," Jesper Strøm explains.
LUMI has great potential, and it wasn't as daunting as the two young men initially thought. "We should have been a bit more careful with our SLURM scripts because we couldn't always estimate how many GPU hours they would consume. There's a calculation that wasn't always straightforward to understand. Fortunately, the sandbox had great flexibility, and DeiC was quick to allocate us additional resources."
"It might have a steep learning curve at the beginning, but I would still recommend just diving in" Andreas advises. "It might seem overwhelming at first, but once you try it and run some tasks, you'll realize that the principles are actually quite simple."
Resources
1. LUMI supercomputer: https://www.lumi-supercomputer.eu
2. Apply for resources on LUMI: https://www.deic.dk/en/supercomputing/Apply-for-HPC-resources
3. HPC/LUMI Sandbox: https://www.deic.dk/en/Supercomputing/Instructions-and-Guides/Access-to-HPC-Sandbox
4. SLURM Learning: https://www.deic.dk/en/news/2022-11-21/virtual-slurm-learning-environment-ready
5. Cotainr for LUMI: https://www.deic.dk/en/news/2023-9-20/cotainr-tool-should-make-it
6. GitLab tools developed for pre-processing of sleep data on LUMI: https://gitlab.au.dk/tech_ear-eeg/common-sleep-data-pipeline




